vLLM Backend
vLLM is a high-performance inference engine designed to efficiently serve Large Language Models (LLMs) in production environments.
In Cube AI, vLLM can be used as a backend to provide scalable, predictable, and efficient model inference for enterprise workloads.
Cube AI Scope
Cube AI scope
Cube AI integrates vLLM as an inference backend. Cube AI does not develop, modify, or extend vLLM itself. Its responsibility is to provide secure access, routing, and execution of vLLM-backed models inside Trusted Execution Environments (TEEs).
Cube AI does not:
- implement model training
- modify model weights
- manage GPU-level optimizations directly
What Is vLLM?
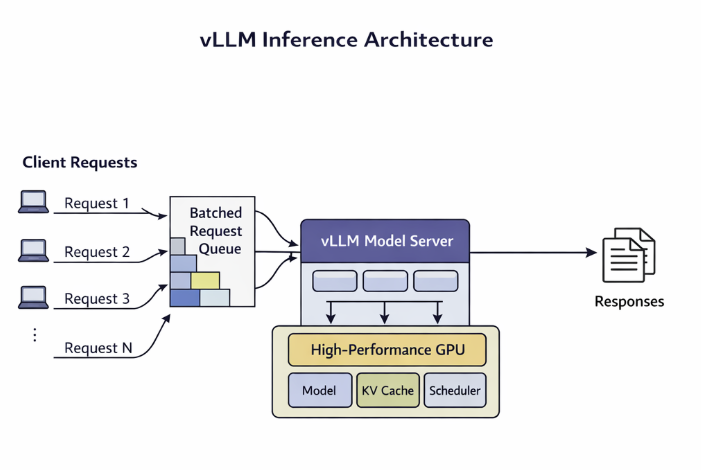
vLLM is an open-source LLM inference engine optimized for:
- high throughput
- concurrent request handling
- efficient GPU memory usage
- predictable latency under load
It is commonly used to serve large language models in production systems.
Why Use vLLM in Cube AI?
Using vLLM as a backend allows Cube AI to:
- serve larger models reliably
- handle multiple parallel inference requests
- provide stable performance characteristics
- support enterprise-scale workloads
vLLM is particularly suitable for:
- chat-based applications
- API-driven inference
- multi-user environments
- high-demand production systems
vLLM vs Ollama
Cube AI supports multiple backends. The choice depends on workload needs.
vLLM
- optimized for throughput and concurrency
- better suited for production and large models
- typically GPU-backed
- operator-managed deployments
Ollama
- simpler setup
- suitable for development and experimentation
- typically used with smaller models
- easier local workflows
Both backends are exposed through the same Cube AI APIs.
How Cube AI Uses vLLM
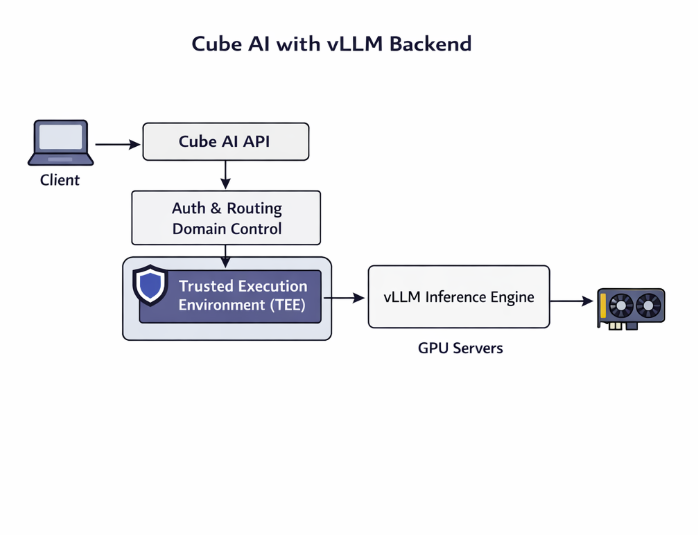
When vLLM is configured as a backend:
- Models are deployed and managed by the operator
- Cube AI routes inference requests to vLLM
- Requests are authenticated and domain-scoped
- Inference is executed inside a Trusted Execution Environment
- Results are returned to the client
Cube AI ensures isolation and access control around vLLM execution.
Model Availability
Models exposed through vLLM depend on:
- vLLM runtime configuration
- models deployed by the operator
- hardware availability (e.g. GPU)
Each Cube AI domain has an isolated view of available vLLM models.
Notes
- vLLM is an optional backend
- Availability depends on deployment configuration
- Cube AI provides API compatibility regardless of backend
- vLLM usage is transparent to API clients
Next Steps
- Explore available Models
- Use vLLM-backed models with Chat Completions
- Apply AI Guardrails for secure inference