Architecture
Cube AI is built on a secure, scalable architecture designed to run Large Language Models (LLMs) inside Trusted Execution Environments (TEEs) while providing isolation between tenants, strong authentication, flexible backend support (Ollama and vLLM), and a unified API surface.
Below is the architecture diagram created by the team:
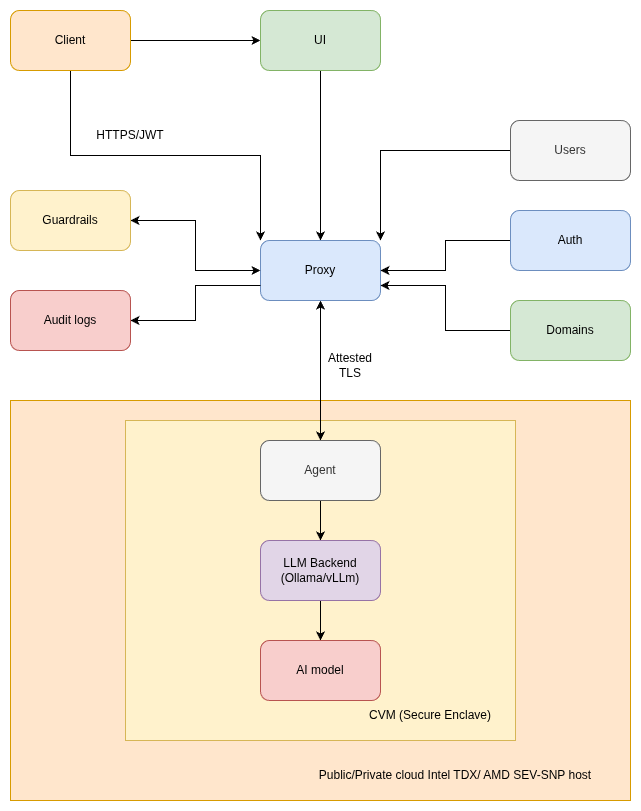
Core Components
Cube AI consists of five primary components:
-
SuperMQ Services
- Users Service
- Auth Service
- Domains Service
-
Cube Proxy
- Secure request gateway
- Domain-based routing
- TEE access enforcement
- Token validation
-
Guardrails Service
- Input validation and filtering
- Output sanitization
- PII detection and redaction
- Jailbreak and prompt injection protection
-
LLM Backend
- Ollama
- vLLM
-
Trusted Execution Environment (TEE)
- Protects models
- Protects prompts and responses
- Ensures confidentiality and integrity
1. SuperMQ (Users, Auth, Domains)
Cube AI uses SuperMQ’s microservices as its identity and tenant-management layer.
✔ Users Service
Stores user accounts, profile data, and associated metadata.
✔ Auth Service
Issues JWT access tokens and validates them.
Cube Proxy uses this service to authenticate every request.
✔ Domains Service
Each domain represents an isolated tenant (workspace).
Models, permissions, and policies are scoped per domain.
Why this matters
SuperMQ allows Cube AI to remain fully multi-tenant, scalable, and secure without duplicating identity logic.
2. Cube Proxy
The Cube Proxy is the central entry point for all LLM-related traffic.
It is responsible for:
- Verifying JWT tokens using the SuperMQ Auth Service
- Checking user permissions and domain membership
- Routing requests to the correct backend based on domain configuration
- Enforcing that all inference requests are executed inside a Trusted Execution Environment
- Normalizing requests to an OpenAI-compatible API shape
3. Guardrails Service
The Guardrails Service provides AI safety controls for all LLM interactions.
What Guardrails Protect Against
- Jailbreak attempts
- Prompt injection
- Toxic content
- PII exposure
- Harmful content
Key Features
- Input validation
- Output sanitization
- PII detection (Microsoft Presidio)
- Hot-reload of rules
- Versioned configurations
4. LLM Backends (Ollama & vLLM)
Ollama
- Lightweight, local-friendly model runner
- Ideal for development environments
vLLM
- High-performance CUDA-accelerated inference
- Designed for production workloads
5. Trusted Execution Environment (TEE)
What the TEE protects
- User prompts
- Model weights
- Intermediate state
- Responses before leaving the enclave
Key guarantees
- Confidentiality
- Integrity
- Remote attestation (powered by the Cocos AI attestation stack)
End-to-End Request Flow
- Client UI / API Client / Continue (VS Code)
- Cube Proxy
- Trusted Execution Environment
- LLM Backend (Ollama or vLLM)
- Trusted Execution Environment
- Cube Proxy
- Client
Summary
Cube AI combines:
- SuperMQ for identity and domain management
- A secure Cube Proxy for routing and authorization
- Guardrails Service for AI safety and compliance
- Flexible backend support (Ollama, vLLM)
- Trusted Execution Environments for confidential LLM execution